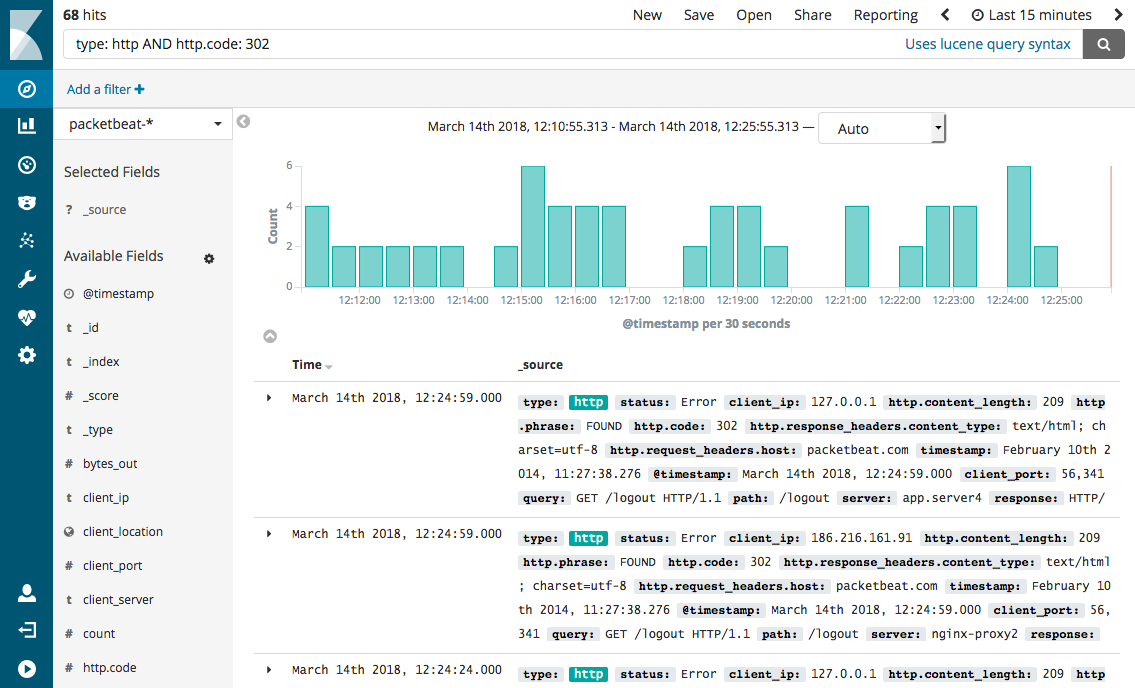
Существуют сотни баз данных SQL и NoSQL. Одни популярны, другие игнорируются. Некоторые просты и хорошо документированы, а некоторые сложны в использовании. Одни имеют открытый код, а другие проприетарные. Что, возможно, наиболее важно, некоторые масштабируемы, оптимизированы, высокодоступны, а некоторые сложно масштабировать или поддерживать.
Возникает естественный вопрос: какую базу данных выбрать? Чтобы ответить на него, мы должны решить, чего мы хотим достичь с помощью базы данных. Чтобы составить представление, необходимо ответить на следующие вопросы:
- Нужен ли нам аналитический доступ к базе данных?
- Нужно ли нам писать или читать в реальном времени?
- Сколько таблиц / записей мы хотим сохранить?
- Какая доступность нам нужна?
- Нужны ли нам столбцы?
- Сможем ли мы получить доступ к таблицам, отфильтрованным по столбцам или по строкам?
Принимая решение, нужно помнить, что может предложить та или иная база данных. Специфика каждой БД может отличаться, но в целом существует только несколько типов, в рамках которых мы можем достичь в основном одинаковых целей. Рассмотрим их подробнее.
Реляционные базы данных SQL
Если вы когда-либо работали с базами данных, скорее всего, вы начали с этого типа, потому что он самый популярный и распространенный. Такие БД позволяют хранить данные в реляционных таблицах с определенными столбцами определенного типа. Реляционные таблицы хороши для нормализации и объединения.
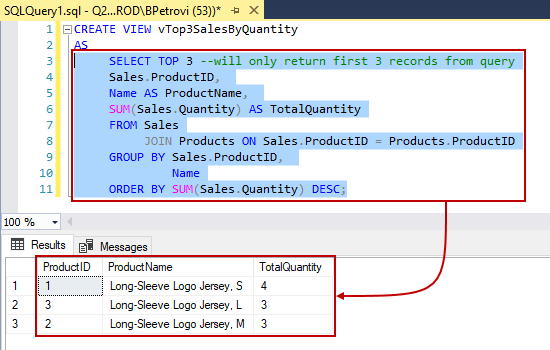
Достоинства:
- Поддержка SQL
- ACID-транзакции (атомарность, согласованность, изоляция и долговечность)
- Поддержка индексации и разделения
Недостатки:
- Плохая поддержка неструктурированных данных / сложных типов
- Плохая оптимизация обработки событий
- Сложное / дорогое масштабирование
Примеры: Oracle DB, MySQL, PostgreSQL.
Документно-ориентированные базы данных
Если мы не хотим объединять несколько таблиц для получения нужных данных, мы можем взглянуть на документно-ориентированные базы данных. Они позволяют хранить записи в формате JSON. В этом формате мы можем создать сложное значение для любого ключа и сразу включить всю структуру данных в одну запись.

Достоинства:
- Нет привязки к схеме
- Нет необходимости всегда писать все поля в каждой записи
- Хорошая поддержка сложных типов
- Подходит для OLTP
Недостатки:
- Плохая поддержка транзакций
- Слабая аналитическая поддержка
- Сложное / дорогое масштабирование
Примеры: MongoDB.
Базы данных в оперативной памяти
Базы данных этого типа могут предоставлять в реальном времени ответ для выбора и вставки определенных записей. Большинство из них в основном хранят данные в ОЗУ, но в некоторых случаях они также предлагают постоянное хранилище на жестких дисках или твердотельных накопителях. Большинство этих баз данных работают с записями «ключ-значение», поэтому значения можно запоминать в формате, ориентированном на документы. Но некоторые базы данных также работают со столбцами и позволяют вторичное индексирование той же таблицы. Использование ОЗУ позволяет обрабатывать данные быстро, но делает их более нестабильными и дорогостоящими.
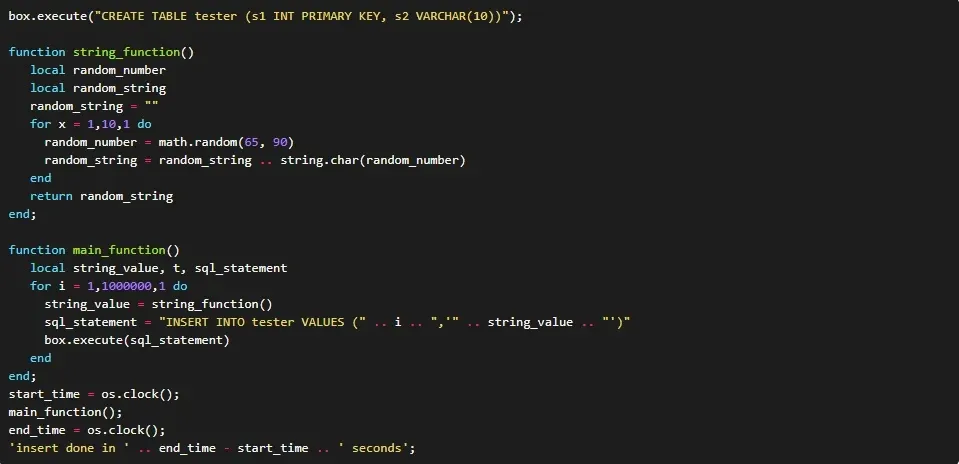
Достоинства:
- Быстрое написание
- Быстрое чтение
Недостатки:
- Труднодостижимая надёжность
- Дорогое масштабирование
Примеры: Redis, Tarantool, Apache Ignite.
Базы данных с широкими столбцами
Эти базы данных хранят данные в виде записей ключ / значение на жестком диске или твердотельном накопителе. Эти решения предназначены для достаточно хорошего масштабирования, чтобы управлять петабайтами данных на тысячах общих серверов в распределенной системе. Они представляют архитектуру SSTable. Эта архитектура была разработана для двух случаев использования: быстрый доступ к ключу и быстрая запись с высокой доступностью.
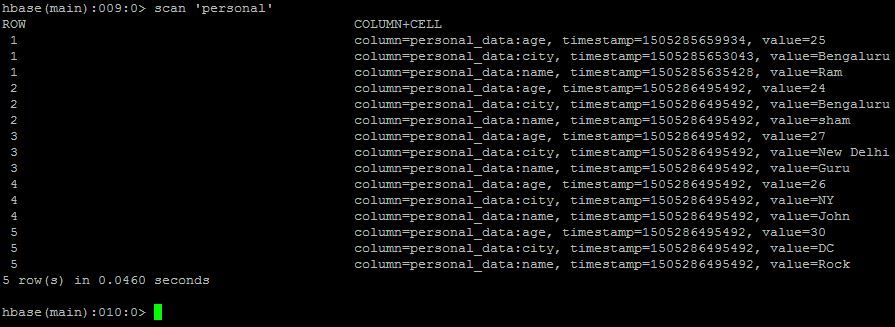
Достоинства:
- Быстрая запись построчно
- Быстрое чтение по ключу
- Хорошая масштабируемость
- Высокая доступность
Недостатки:
- Формат «ключ-значение»
- Нет поддержки аналитики
Примеры: Cassandra, HBase.
Столбчатые базы данных
Иногда нам нужно быстро получить доступ к данным не с помощью определенных ключей, а с помощью определенных столбцов. В этом случае лучше отказаться от построчной вставки и перейти к пакетной записи. Пакетная вставка позволяет столбчатым базам данных готовить данные для быстрого чтения по столбцам.
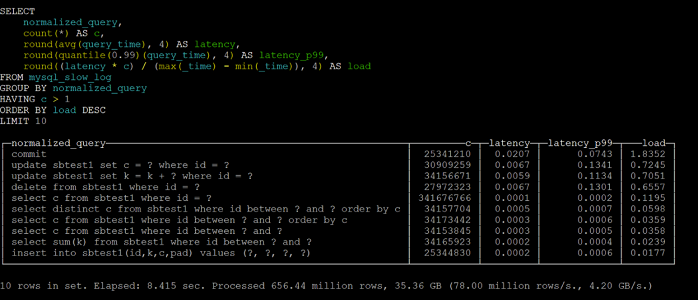
Достоинства:
- Быстрое чтение столбец за столбцом
- Хорошая аналитическая поддержка
- Хорошая масштабируемость
Недостатки:
- Подходит только для пакетных вставок
Примеры: Vertica, Clickhouse.
Поисковая система
Если мы хотим получить доступ к данным с помощью фильтра по любому значению и даже по любому слову в столбце, мы должны вспомнить про поисковые системы. Эти базы данных выполняют индексацию каждого слова в столбцах и позволяют выполнять полнотекстовый поиск. Они идеально подходят для хранения и анализа журналов или больших текстовых значений.
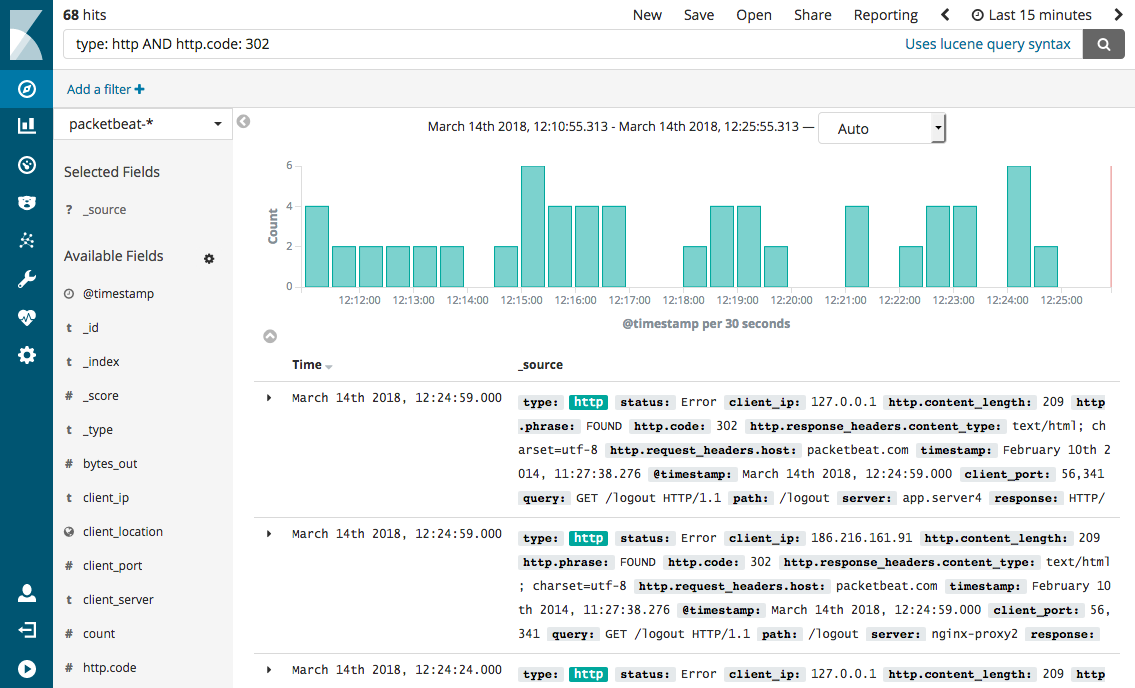
Достоинства:
- Быстрый доступ по любому слову
- Хорошая масштабируемость
Недостатки:
- Подходит только для пакетных вставок
- Плохая аналитическая поддержка
Примеры: Elastic.
Графовые базы данных
Для некоторых случаев подходят графовые структуры данных. Если ваши задачи требуют работы с графами, существуют специальные базы данных, которые удовлетворят ваши потребности.
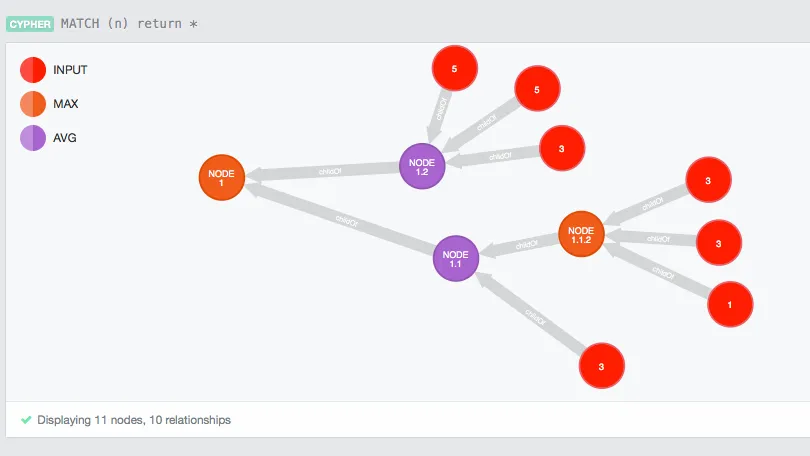
Достоинства:
- Структура данных графа
- Управляемые отношения между сущностями
- Гибкие конструкции
Недостатки:
- Специальный язык запросов
- Трудно масштабировать
Примеры: Neo4j.


Практически любую задачу можно выполнить практически с любым типом базы данных. Вопрос в том, насколько это будет дорого и оптимизировано. Выбор инструмента, к которому вы привыкли, может сократить ваше время вывода на рынок. Но он также может стоить вам огромных денег на обслуживание и расширение вашего оборудования, которое может быть использовано неэффективно. Всегда старайтесь использовать базу данных так, как она задумана. Возможно, решение, соответствующее вашим потребностям, уже существует.






